- En moyenne à travers 39 pays, deux tiers environ (68%) des Africains vivent dans des zones de dénombrement (ZD) desservies par un réseau électrique, allant de 29% à Madagascar à 100% en Tunisie et aux Seychelles (Figure 1).
- Six ménages africains sur 10 (60%) sont effectivement raccordés à un réseau électrique public. Les citoyens des Seychelles et de Maurice bénéficient d'une couverture universelle, mais moins d'un quart des ménages sont connectés à Madagascar (22%) et au Malawi (17%) (Figure 2).
- Moins de la moitié (44%) des Africains bénéficient d'un approvisionnement en électricité qui est disponible « la plupart du temps » ou « tout le temps » (Figure 3). o En moyenne à travers les 33 pays sondés en 2014/2015 et en 2021/2023, cette proportion ne s'est accrue que de 4 points de pourcentage.
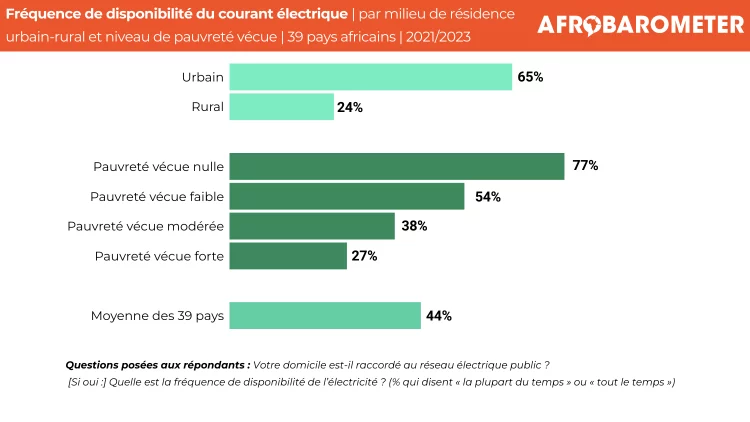
- Un service électrique fiable qui est disponible « la plupart du temps » ou « tout le temps » est beaucoup plus courant dans les villes (65%) que dans les zones rurales (24%) et augmente avec le statut économique des personnes interrogées, allant de 27% des ménages les plus pauvres à 77% des plus riches (Figure 4).
Les progrès en matière d’électrification en Afrique restent lents et inégaux, comme le montre le dernier Profil Panafricain d’Afrobarometer.
Les résultats, basés sur 53.444 entretiens en face-à-face dans 39 pays africains, montrent que des progrès très modestes en matière d’accès et de connexion laissent encore une majorité de ménages sans électricité fiable. Même si les expériences varient considérablement d’un pays à l’autre, en moyenne, moins de la moitié des ménages bénéficient d’un approvisionnement fiable en électricité. Les ménages ruraux et pauvres sont particulièrement désavantagés, non seulement en termes d’accès et de connexion, mais également de qualité de service.
Dans l’ensemble, moins de la moitié des Africains sont satisfaits de la performance de leur gouvernement en matière de fourniture d’électricité.